
학습 중 모델의 성능을 확인하고 문제 영역을 파악합니다. 이미지, 동영상, 오디오, 3D 오브젝트를 포함한 리치 미디어를 지원합니다.
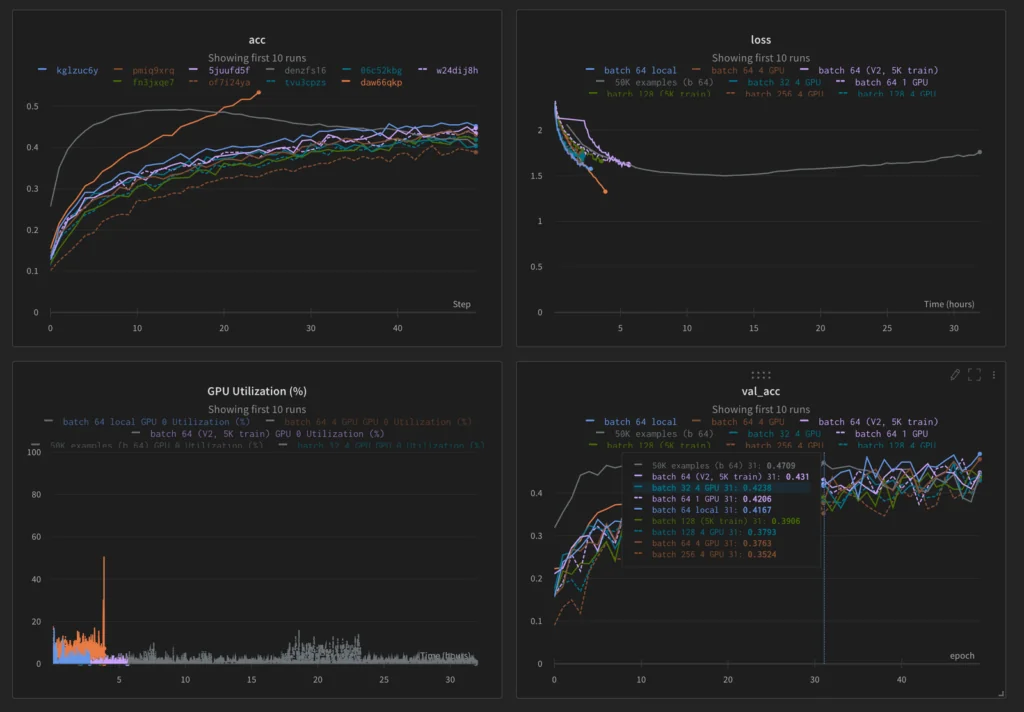
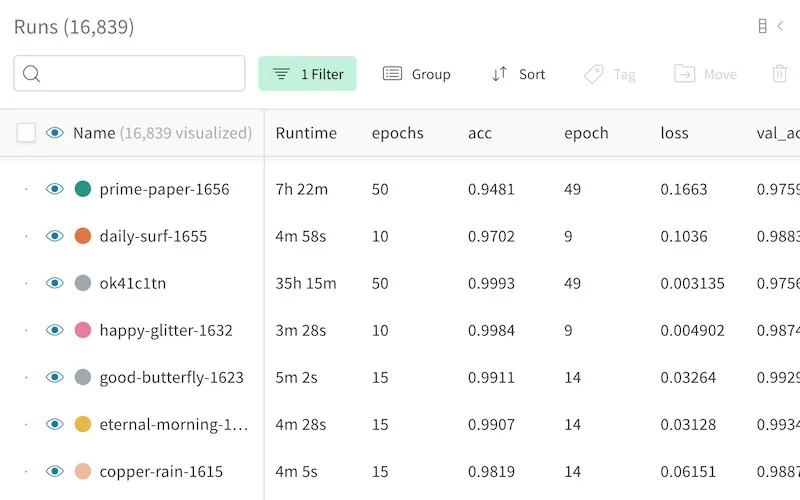
모델 메트릭을 대화형 그래프와 표로 실시간 스트리밍합니다. 모델을 학습하는 위치에 관계없이 최신 ML 모델이 이전 실험과 비교하여 어떤 성능을 발휘하고 있는지 쉽게 확인할 수 있습니다.
W&B 의 실험 추적 기능은 나중에 모델을 재현하는 데 필요한 최신 git 커밋, 하이퍼파라미터, 모델 가중치, 샘플 테스트 예측을 저장합니다.
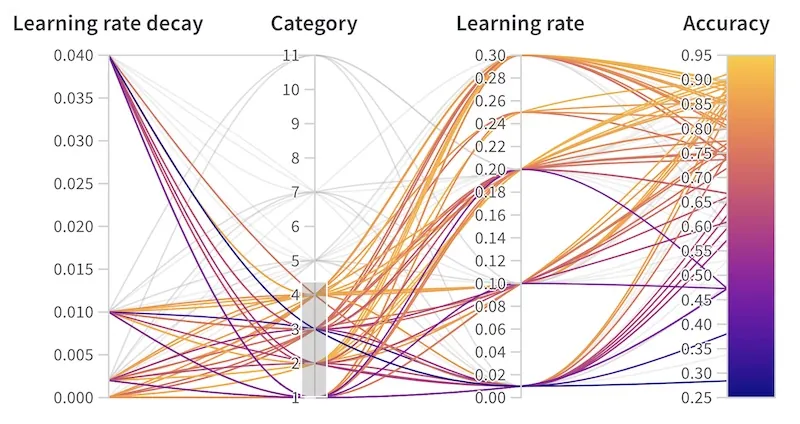
널리 사용되는 알고리즘의 투명한 구현을 사용하거나 Sweeps울 위한 자체 로직을 사용자 정의할 수 있습니다.
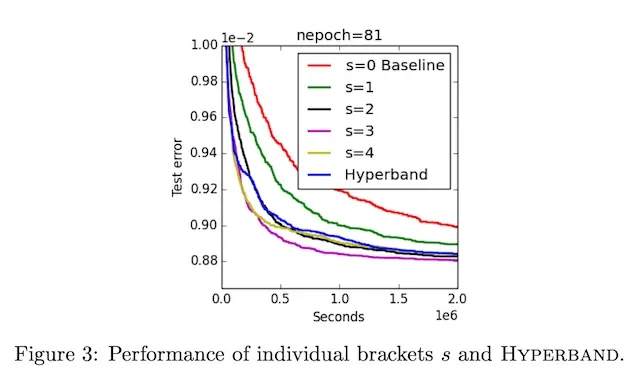
지정 가능한 초기 중지로 GPU 시간을 절약하기 위해 하이퍼밴드 알고리즘을 구현했습니다. 가장 유망하고 성능이 우수한 실행을 계속 실행하고 하위 실행은 종료함으로써 새로운 하이퍼파라미터 조합을 시도할 수 있는 인적, 시간적 자원을 확보할 수 있습니다.
Sweep은 대규모를 처리할 수 있으며 초기 중지를 지원하므로 GPU 시간을 낭비하지 않고 수천 개 이상의 하이퍼파라미터 조합을 빠르게 최적화할 수 있습니다.

어떤 하이퍼파라미터가 관심 있는 메트릭에 영향을 미치는지 시각화하세요. W&B에는 머신 러닝 실험을 비교하기 위해 사용자 지정 코드를 작성하지 않고도 쉽게 시작할 수 있는 기본 시각화가 제공됩니다.
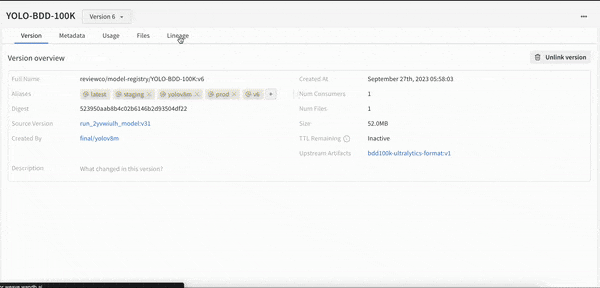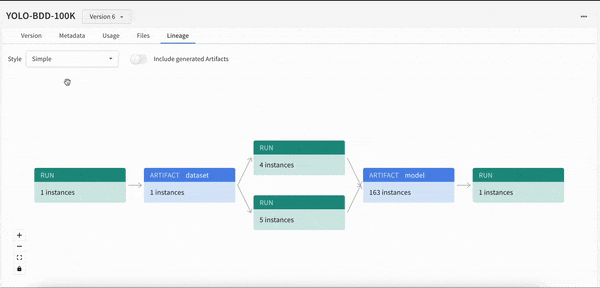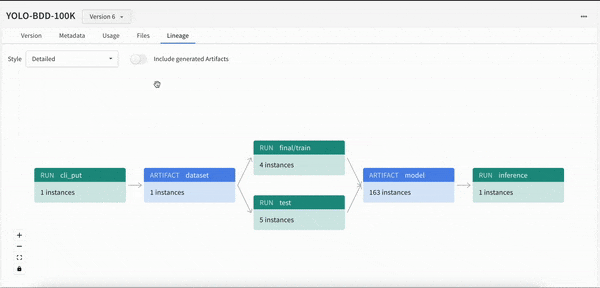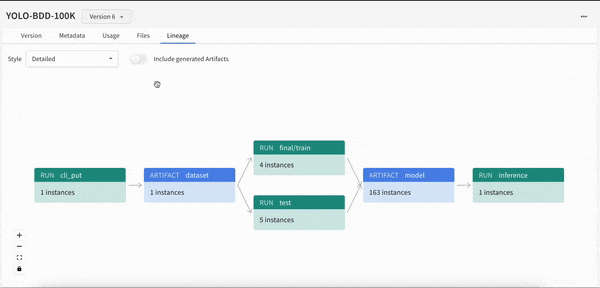
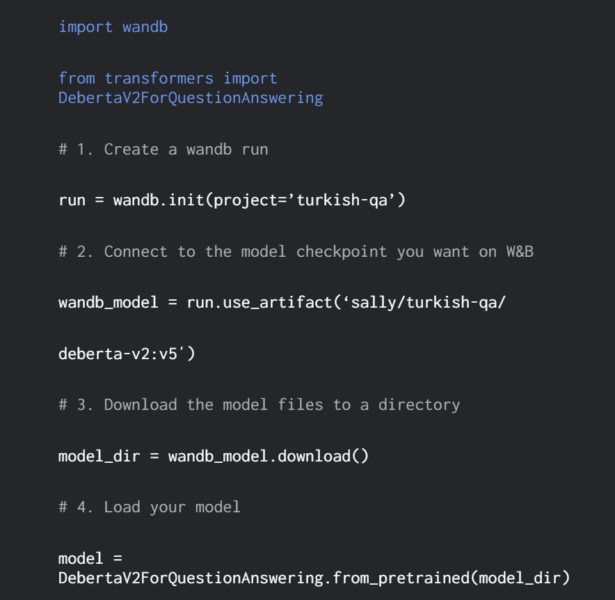
몇 줄의 코드만으로 모델 개발 프로세스에 대한 가시성을 확보할 수 있습니다. 모델 계보를 쉽게 확인하고 “이 모델이 학습한 데이터 세트의 정확한 버전은 무엇인가요?"와 같은 질문에 답할 수 있습니다.
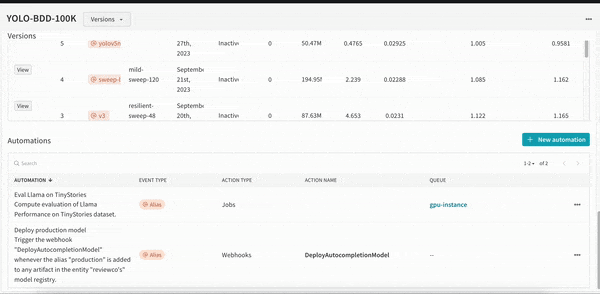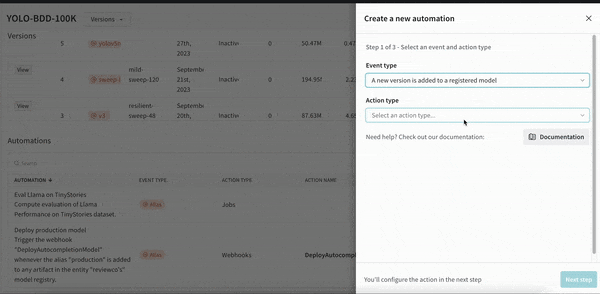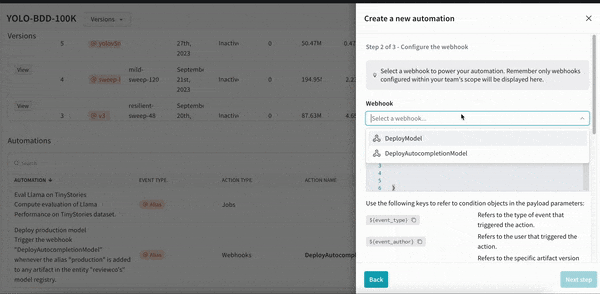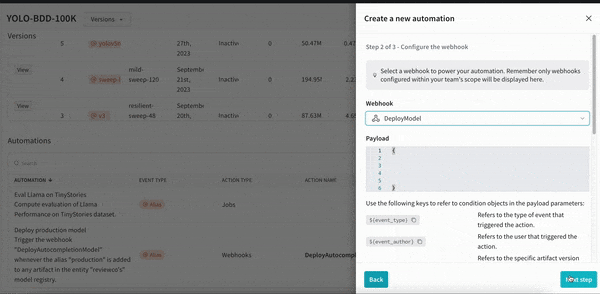
머신러닝 모델을 자동으로 재교육하고 재평가하여 팀의 프로덕션을 최신 상태로 유지합니다. 업데이트 내역을 쉽게 감사하고 모델을 업데이트하기 위해 반복되는 수동 단계를 줄일 수 있습니다.
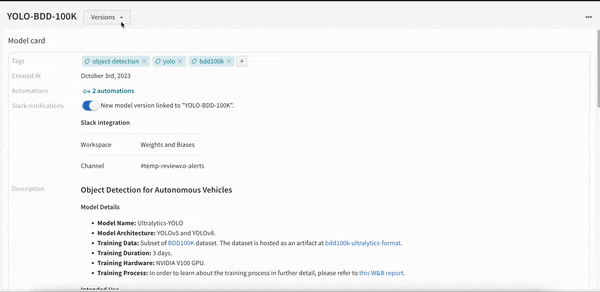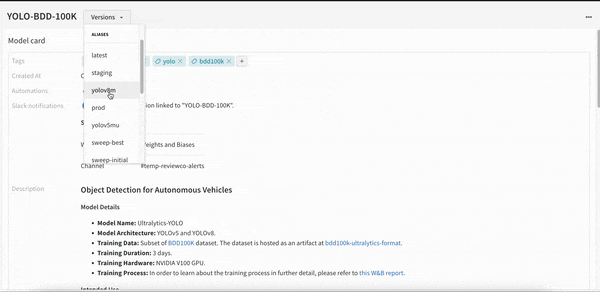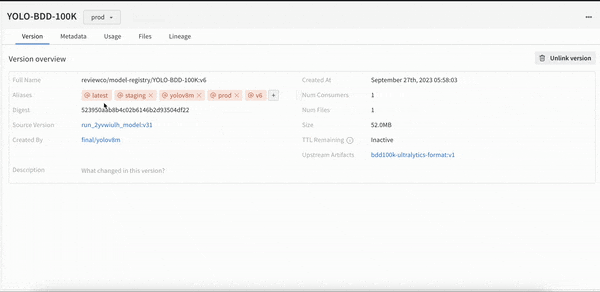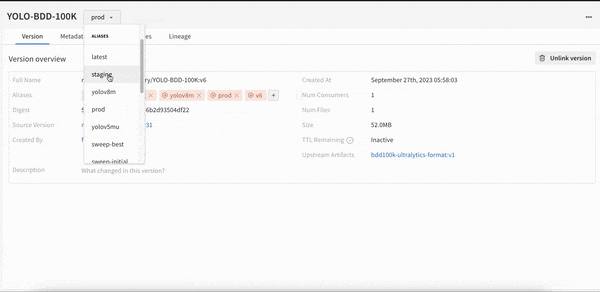
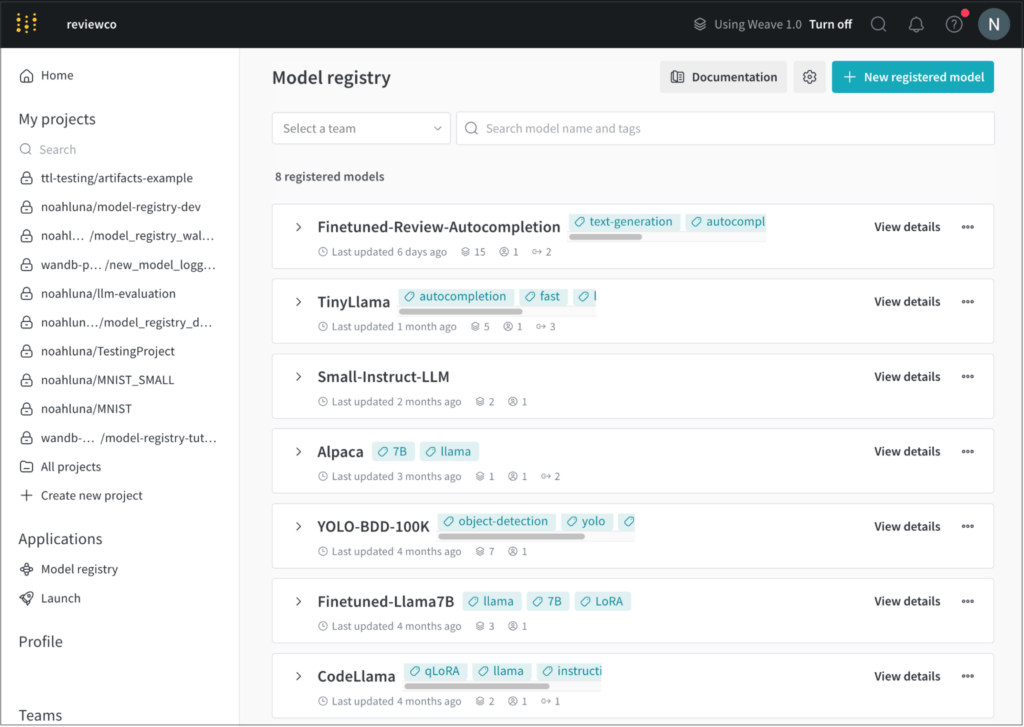
개발부터 스테이징, 프로덕션에 이르는 모든 수명 주기 단계에서 전체 모델 버전을 중앙에서 관리합니다.
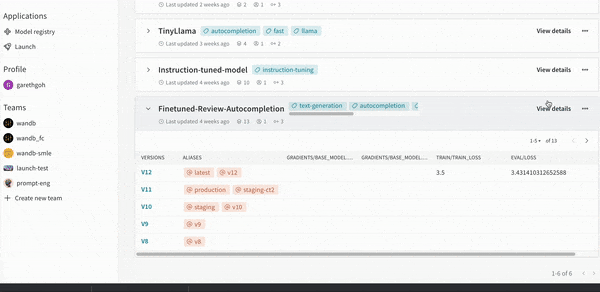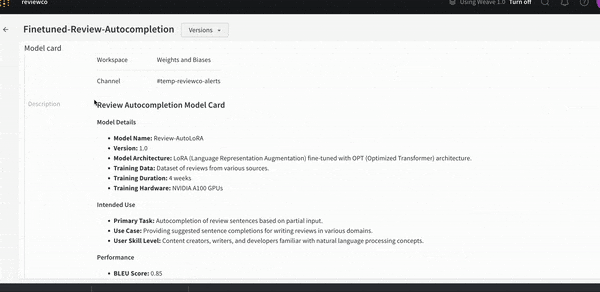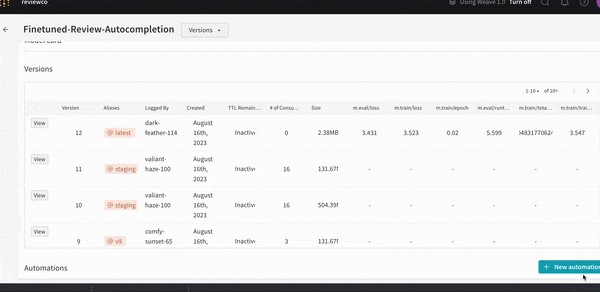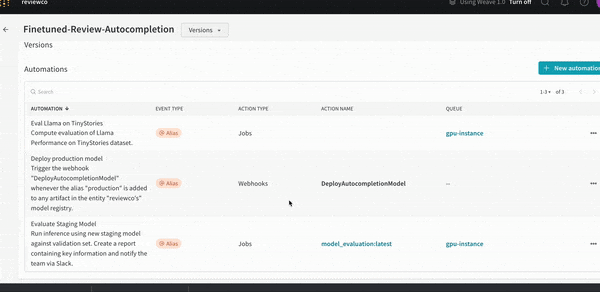
모델 버전 간의 비교를 시각화하여 성능을 평가할 수 있습니다. 모델을 프로덕션에 배포하기 전에 회귀를 식별합니다.
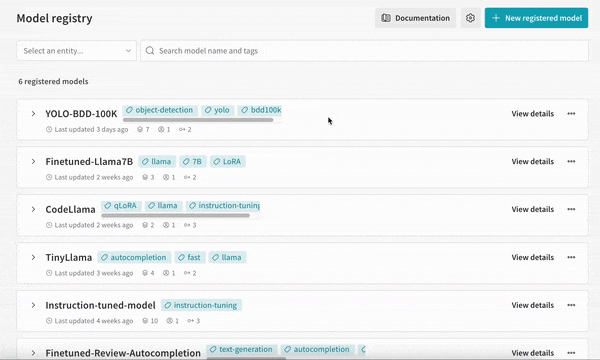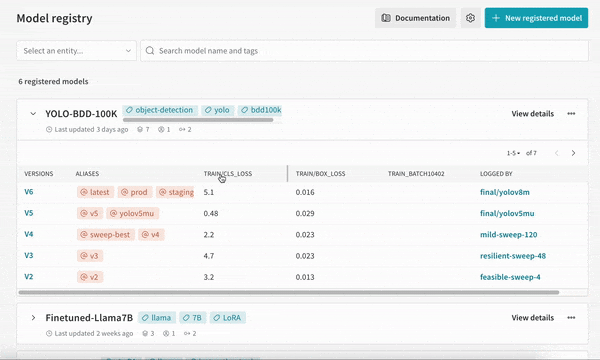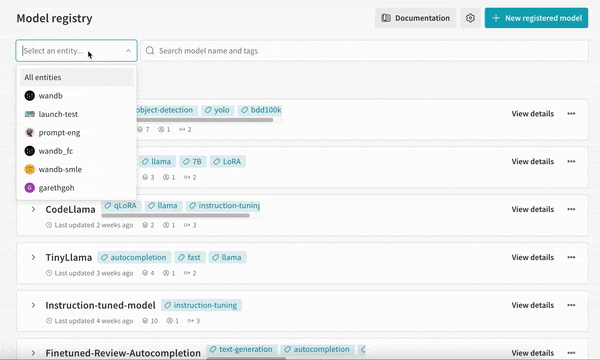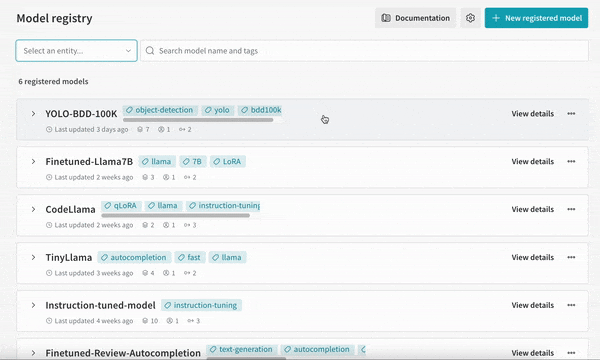
팀 전체가 같은 정보를 공유하면 모델을 더 빠르게 반복할 수 있습니다. W&B의 ML 모델 레지스트리를 사용하면 현재 사용 중인 모델과 새로운 후보 모델을 명확하게 비교할 수 있는 중앙 집중식 데이터 소스를 확보할 수 있습니다.
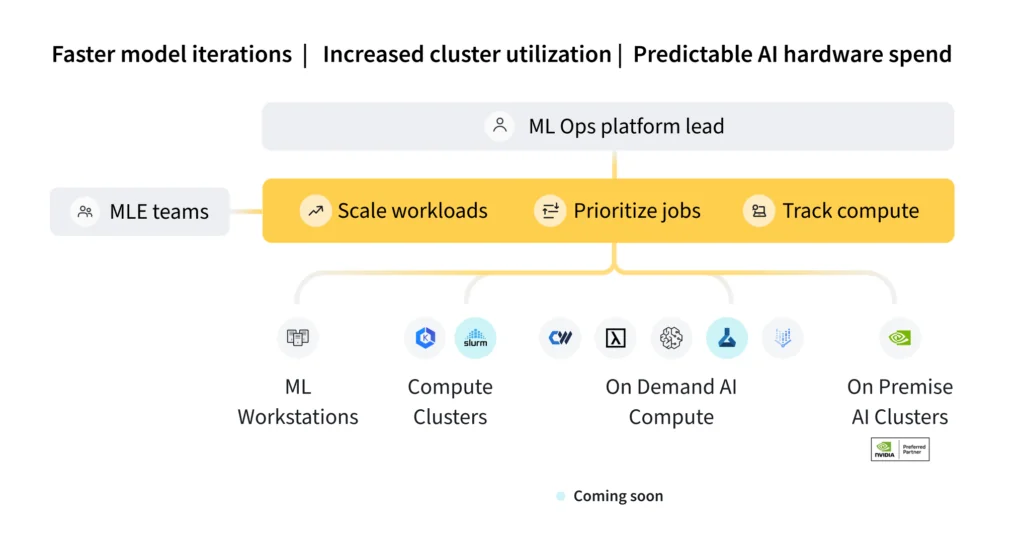
하나의 공통 인터페이스로 조직의 사일로를 제거하세요. 모든 인프라 복잡성을 추상화한 상태에서 필요한 컴퓨팅을 사용할 수 있으며, MLOps는 관리하는 인프라 환경 전반에 걸쳐 감독 및 통합 가시성을 유지합니다.
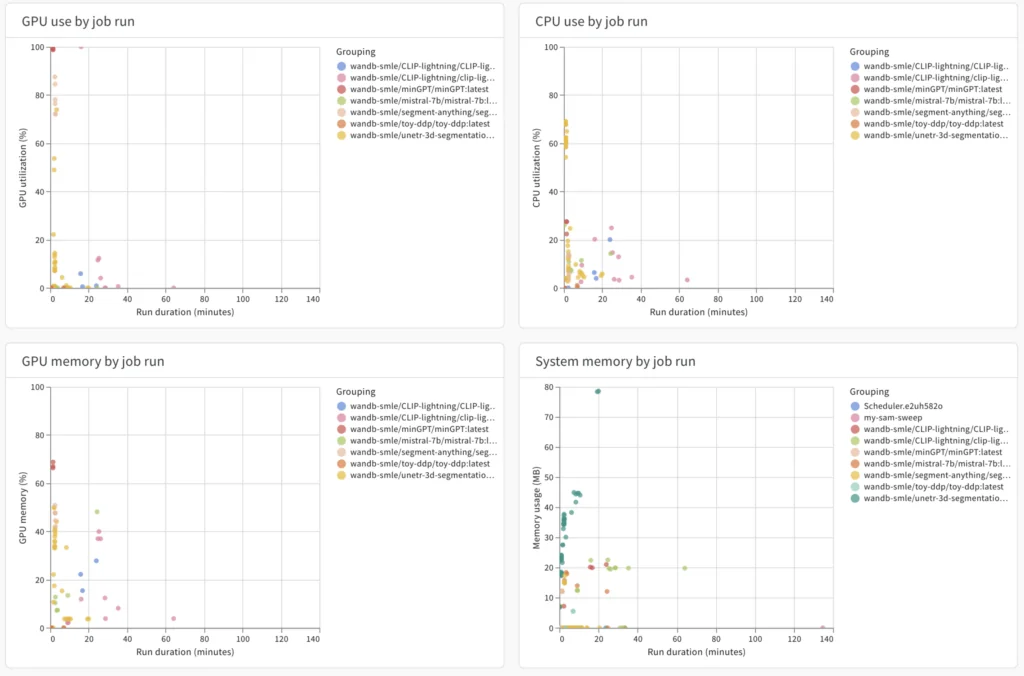
ML 인프라 예산이 어떻게 사용되고 있는지, 또는 활용되지 않고 있는지에 대한 가시성을 높입니다. 중요한 인프라 투자에 대한 지출을 합리화하고 더 나은 기본값을 설정하여 해당 리소스를 최적으로 효율적으로 사용할 수 있습니다.
어떤 대상 환경에서도 작업을 실행하여 로컬 머신에서 분산 컴퓨팅으로 ML 트레이닝 워크로드를 대폭 확장할 수 있습니다. 외부 환경, 더 나은 GPU 및 클러스터에 쉽게 액세스하여 ML 워크플로우의 속도와 예측 가능한 규모를 높일 수 있습니다.
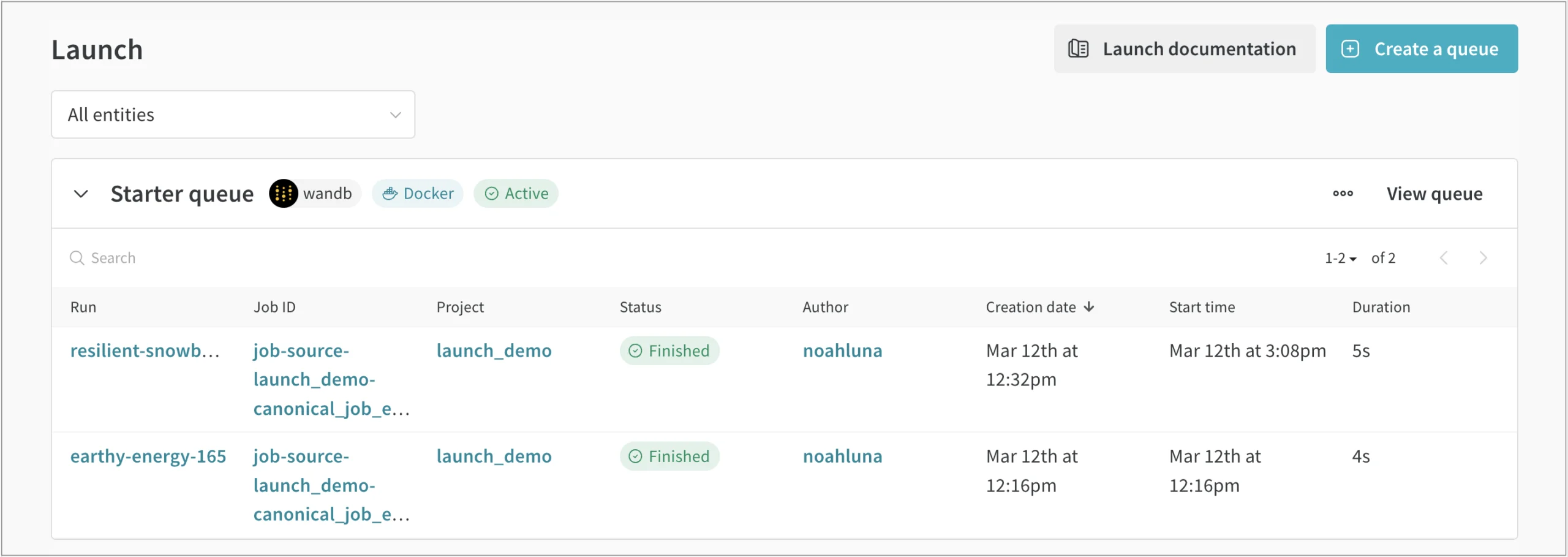
승인된 모델을 프로덕션 추론 환경에 배포하는 주기를 획기적으로 단축합니다. 클릭 한 번으로 실행을 재현하는 기능으로 모델을 더 자주, 더 철저하고 지속적으로 평가할 수 있습니다. 실행 시 Sweeps를 사용하여 작업을 다시 실행하기 전에 노브를 쉽게 조정하고 하이퍼파라미터를 변경할 수 있습니다.
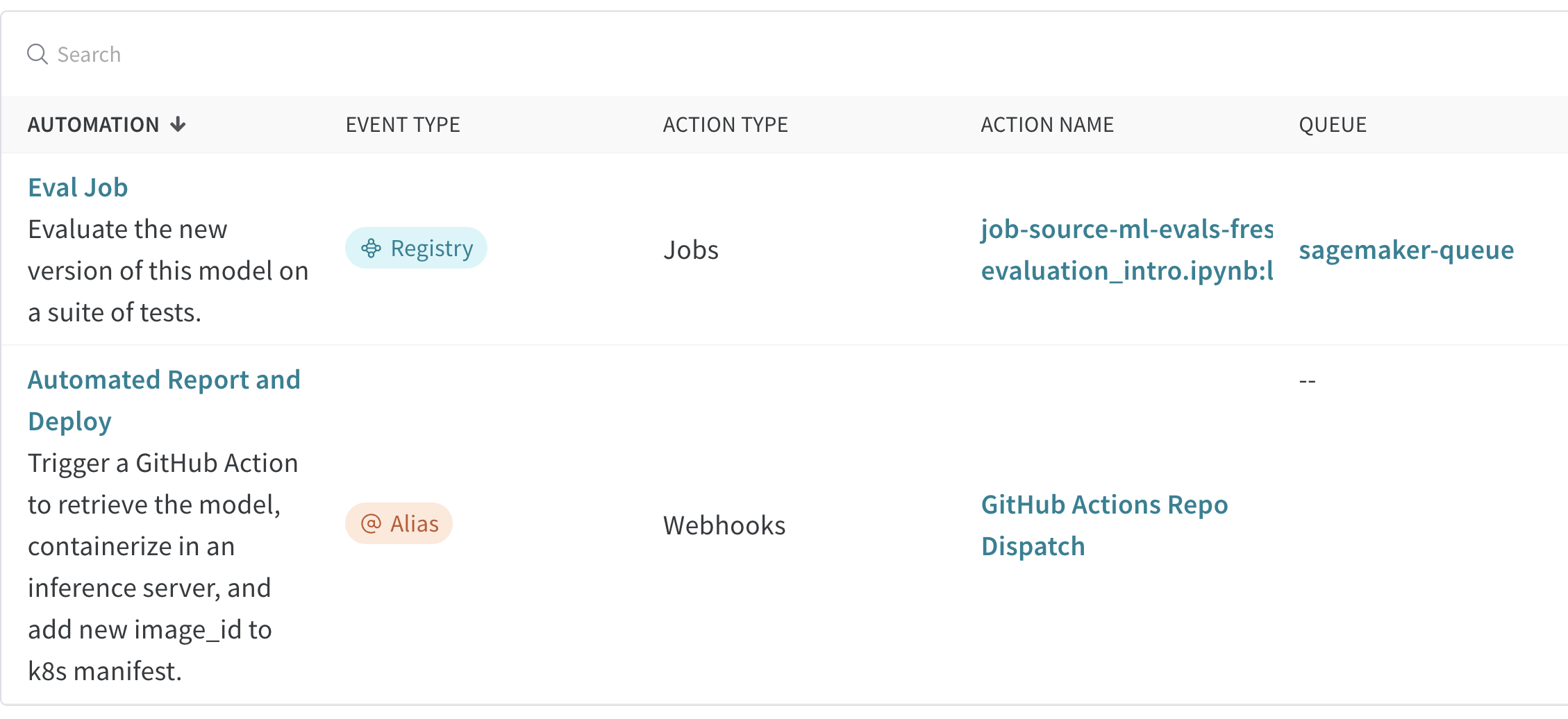
모델 레지스트리에서 주요 이벤트를 트리거하여 평가 또는 배포를 위한 원활하고 자동화된 모델 핸드오버를 보장합니다.
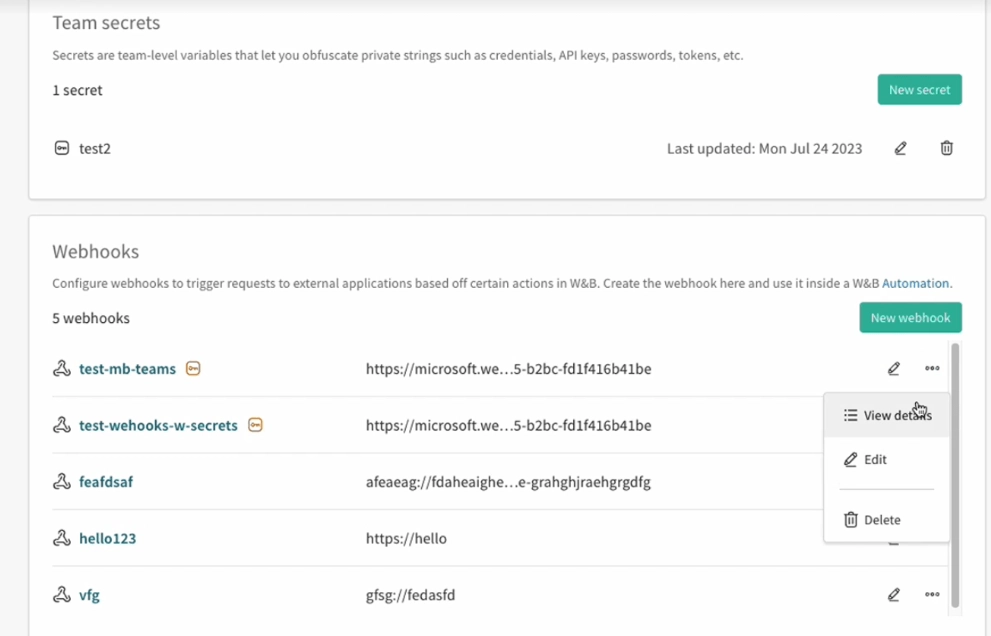
웹훅을 만들 때 인증 또는 권한 부여에 Secrets를 사용하여 완벽한 데이터 개인정보 보호 및 보안을 보장할 수 있습니다. 크리덴셜, API 키, 비밀번호, 토큰 등과 같은 비공개 문자열을 난독화하여 일반 텍스트를 보호합니다.
개발부터 테스트, 배포에 걸쳐 모델 체크포인트를 자동으로 지속적으로 전달하여 항상 프로덕션 환경에서 고성능 모델을 제공합니다. GitHub Action 워크플로를 트리거하여 모델을 활용하고 테스트를 실행할 수 있습니다.

경량 데이터 집합 및 모델 버전 관리
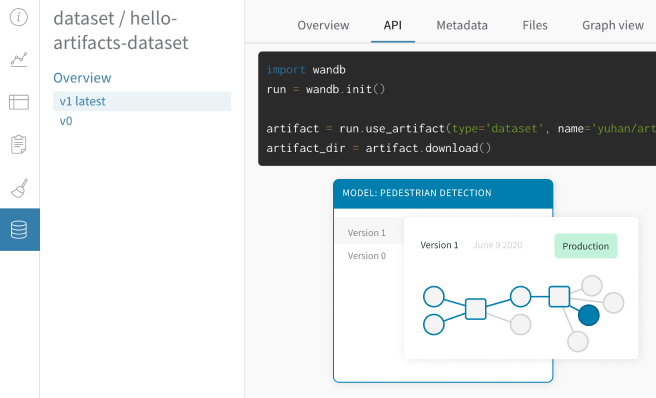
크립트에 몇 줄만 추가하면 온프레미스 또는 클라우드에서 종속성 그래프를 구축할 수 있습니다. 파이프라인을 통해 데이터의 흐름을 추적하여 어떤 데이터 세트가 모델에 공급되는지 정확히 파악할 수 있습니다.
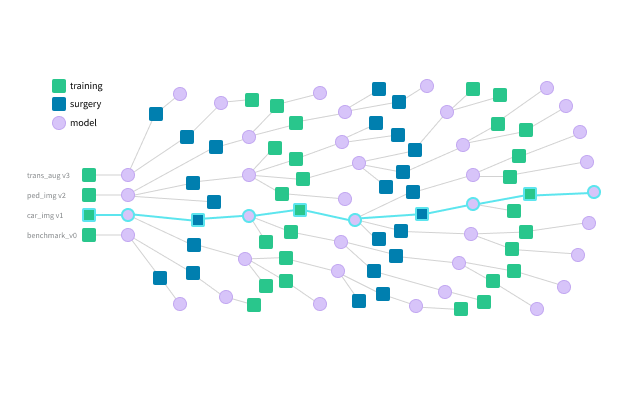
데이터 세트와 모델을 자유롭게 개선할 수 있습니다. 시간이 지남에 따라 데이터의 진화를 추적하고 가장 성과가 좋은 모델의 체크포인트를 보존합니다.
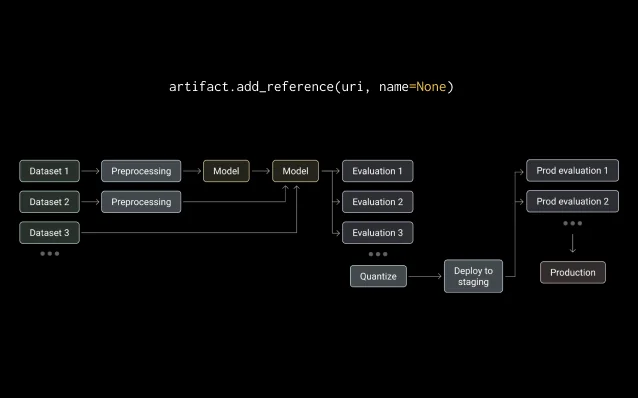
민감한 데이터에 대한 액세스를 규제하고 모니터링할 수 있습니다. 비공개 버킷에 있는 데이터에 대한 참조를 관리하여 파일 내용이 외부로 유출되지 않도록 합니다.
모델 예측 시각화 및 분석
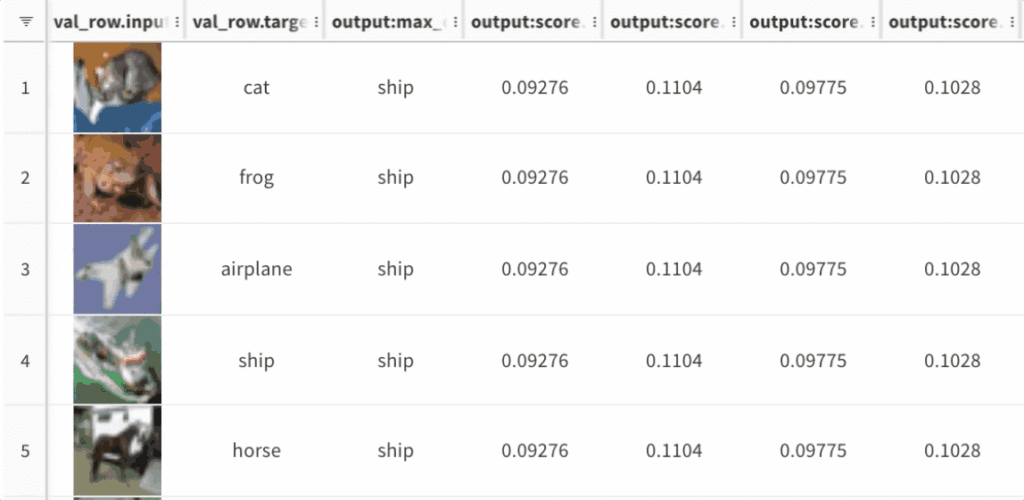
데이터 집합에서 흥미로운 행을 시각화하고 쿼리하세요. 표 형식 데이터에서 그룹화, 정렬, 필터링, 계산된 열을 생성하고 차트를 만들 수 있습니다. 머신 러닝 모델 예측과 그 기반이 되는 데이터 세트를 이해하고 시각화합니다.
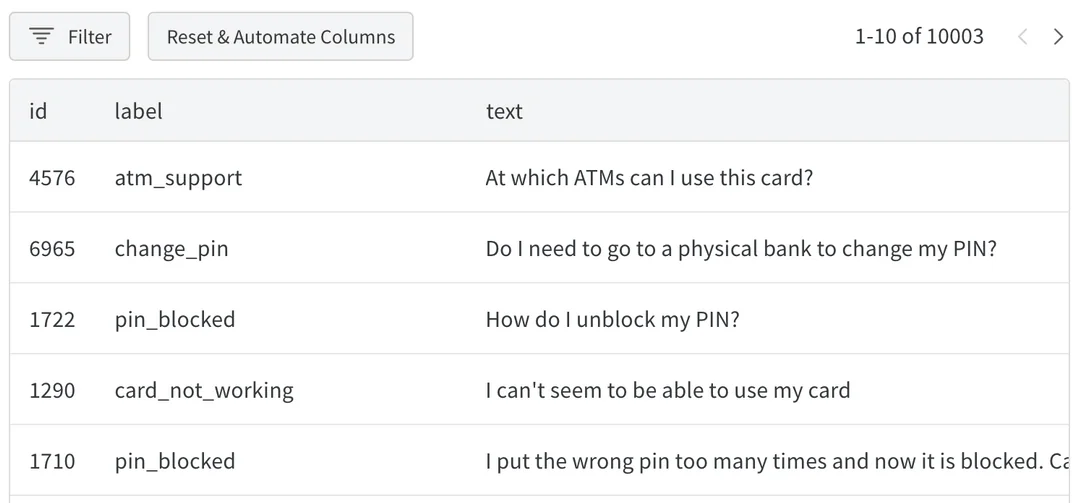
데이터에서 계산된 열을 그룹화, 정렬, 필터링 및 작성하세요. 결과를 저장하여 그룹 정렬 필터와 생성된 히스토그램을 강조 표시합니다.
실시간 대시보드의 협업 분석
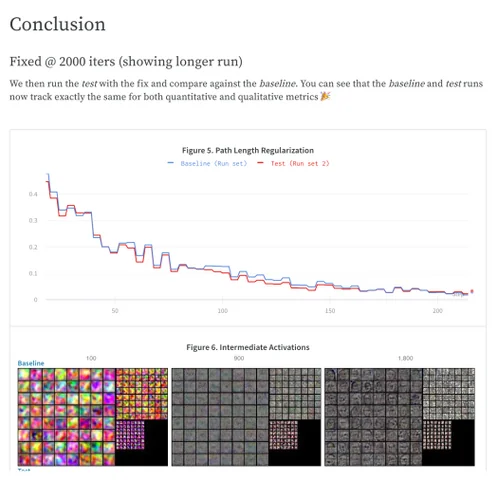
머신 러닝 프로젝트의 업데이트와 결과를 동료들과 공유하는 것이 그 어느 때보다 쉬워졌습니다. 모델 작동 방식을 설명하고, 모델 버전이 어떻게 개선되었는지 그래프와 시각화를 보여주고, 버그에 대해 논의하고, 마일스톤을 향한 진행 상황을 확인할 수 있습니다.

실시간 댓글을 달고, 발견한 내용을 설명하고, 작업 로그의 스냅샷을 찍을 수 있습니다.

스크린샷과 정리되지 않은 노트는 더 이상 필요 없습니다. 리포트를 LaTeX zip 파일로 간편하게 내보내거나 PDF로 변환할 수 있습니다.
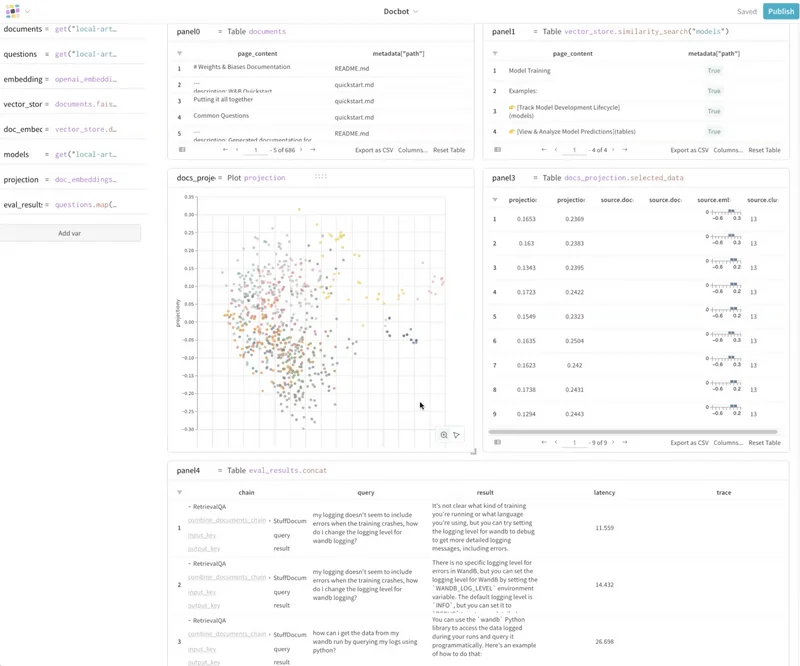
W&B Weave는 머신 러닝 및 데이터 앱 개발을 위한 시각적이고 인터랙티브한 툴킷입니다. 데이터 표로 시작하여 원하는 대화형 대시보드로 끝낼 수 있으며, 그 과정에서 코드와 UI를 쉽게 전환할 수 있습니다. 데이터를 이해하고, 시각화하고, 상호 작용하는 방식을 혁신할 수 있습니다.
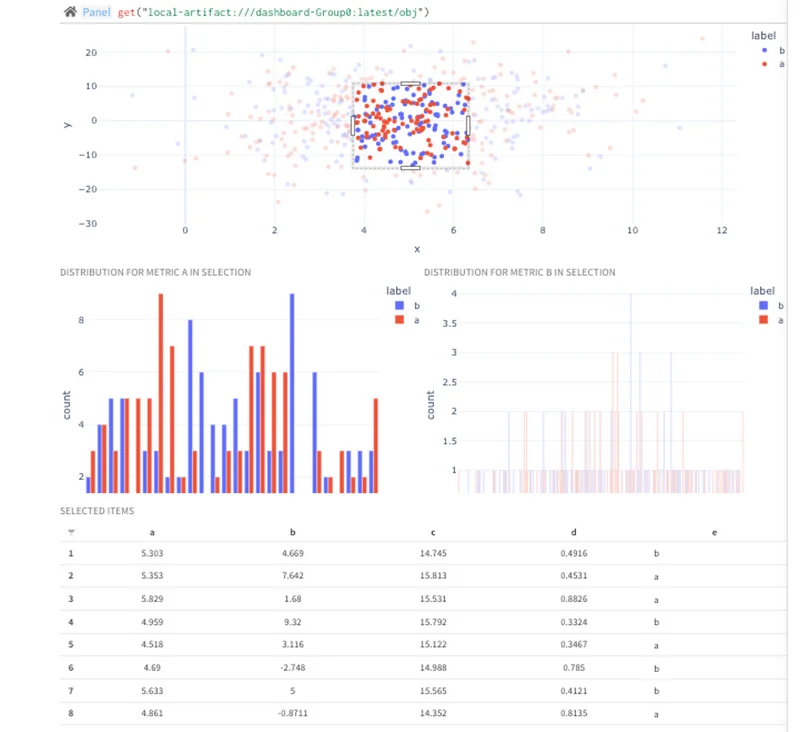
모듈식 구성 요소를 빌드하고 확장할 수 있어 간단하게 시작하고 그 과정에서 정교함을 추가할 수 있습니다. 데이터 탐색부터 모델 구성 비교까지 모든 단계를 공유하고 재사용할 수 있으며, 자체 작업과 ML 에코시스템의 최신 기술을 활용하여 데이터 탐색부터 모델 구성 비교까지 모든 작업을 수행할 수 있습니다.
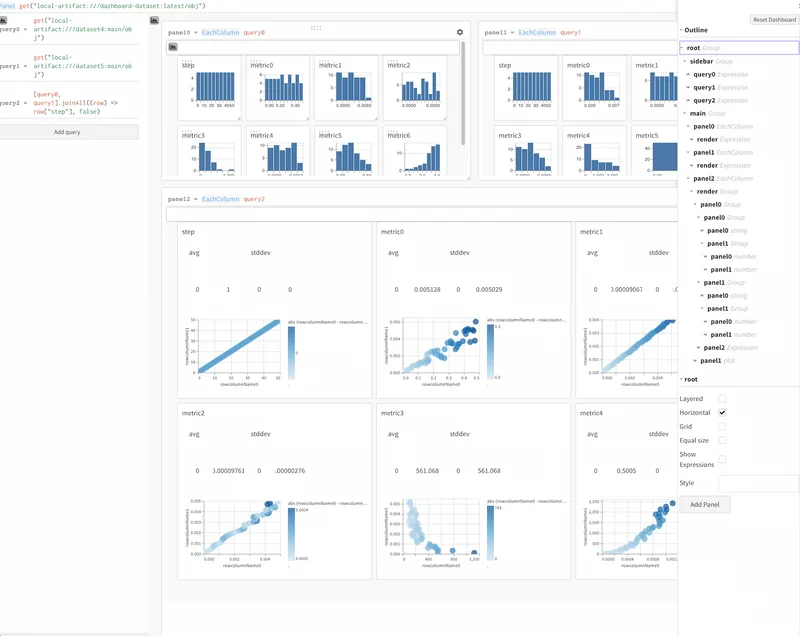
Weave는 머신 러닝 및 데이터 애플리케이션을 구성하도록 특별히 설계되었습니다. 데이터 탐색, 실험, 평가, 모니터링 등을 포함한 엔드투엔드 ML 워크플로우를 직관적으로 구성할 수 있습니다.
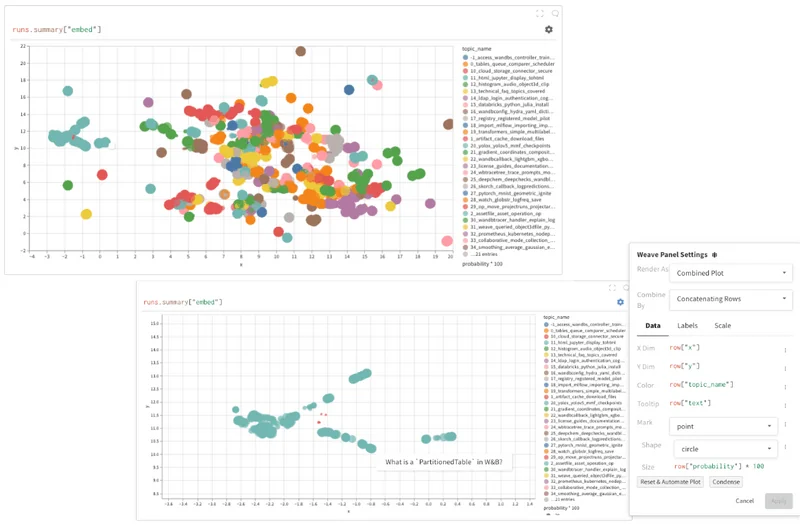
고유한 사용 사례와 문제 도메인에 맞게 사용자 지정할 수 있으므로 모든 대상 또는 이해관계자를 위해 성능과 안정성이 뛰어난 앱을 제작하고 실행할 수 있습니다.