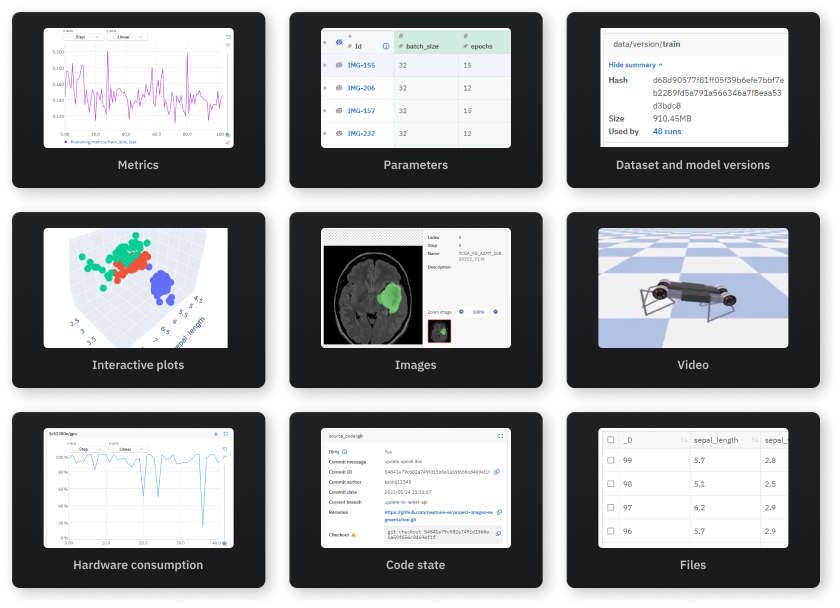
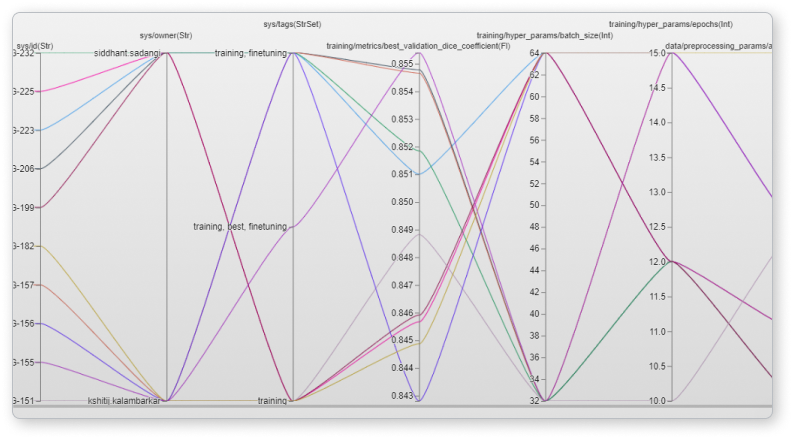
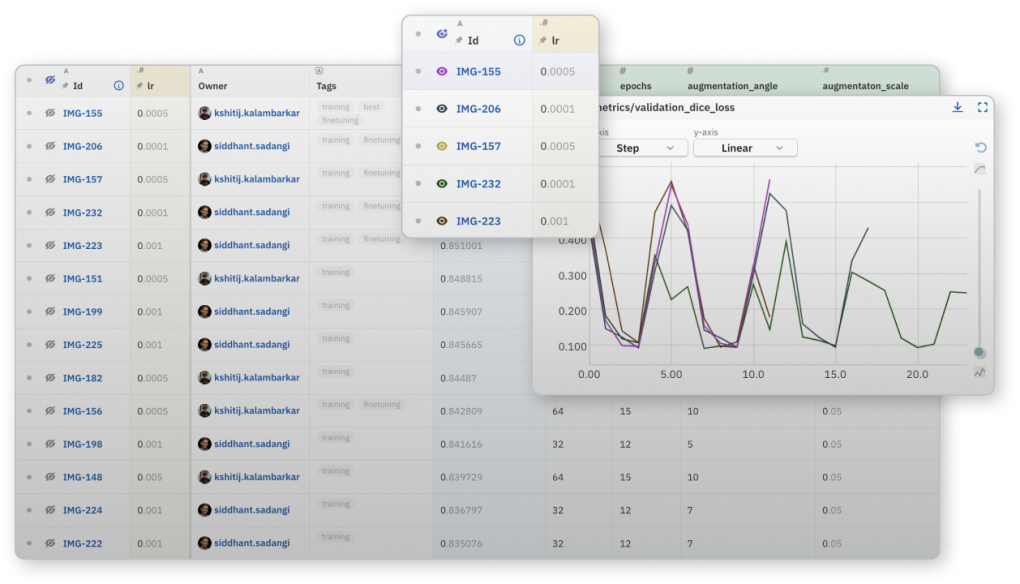
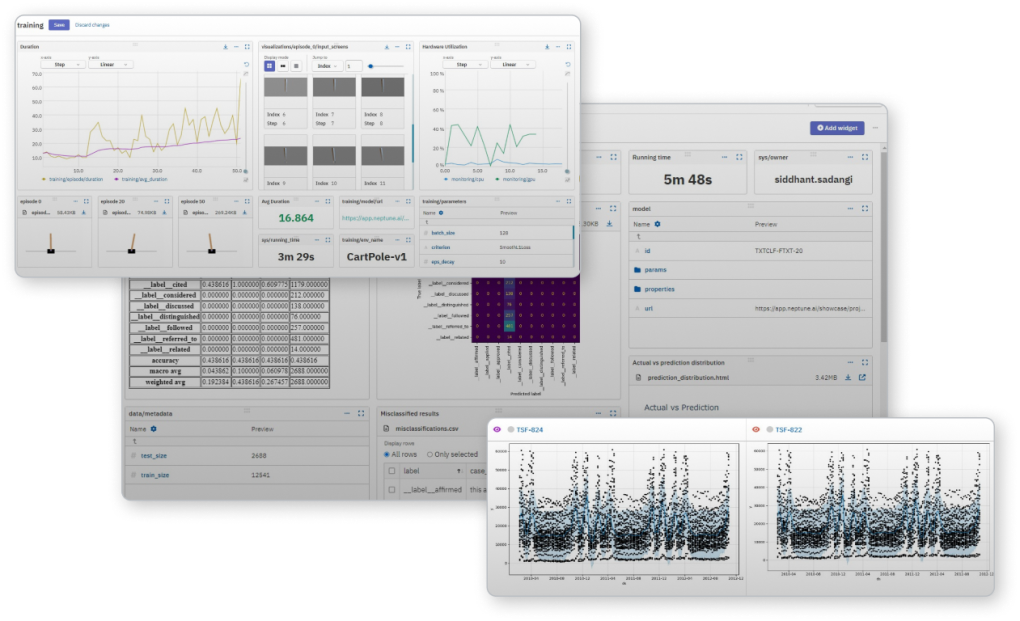
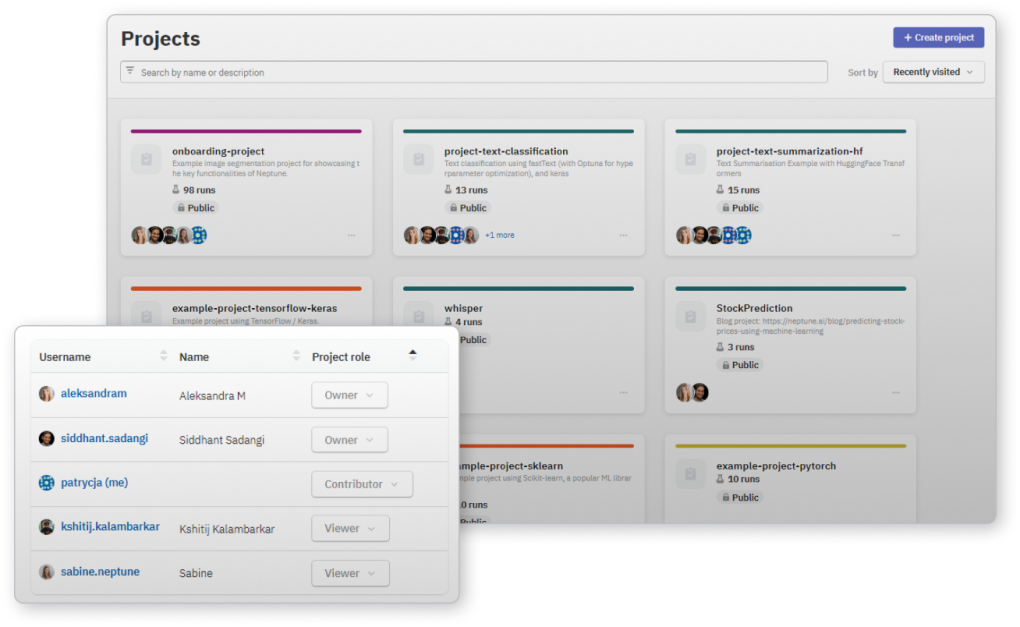
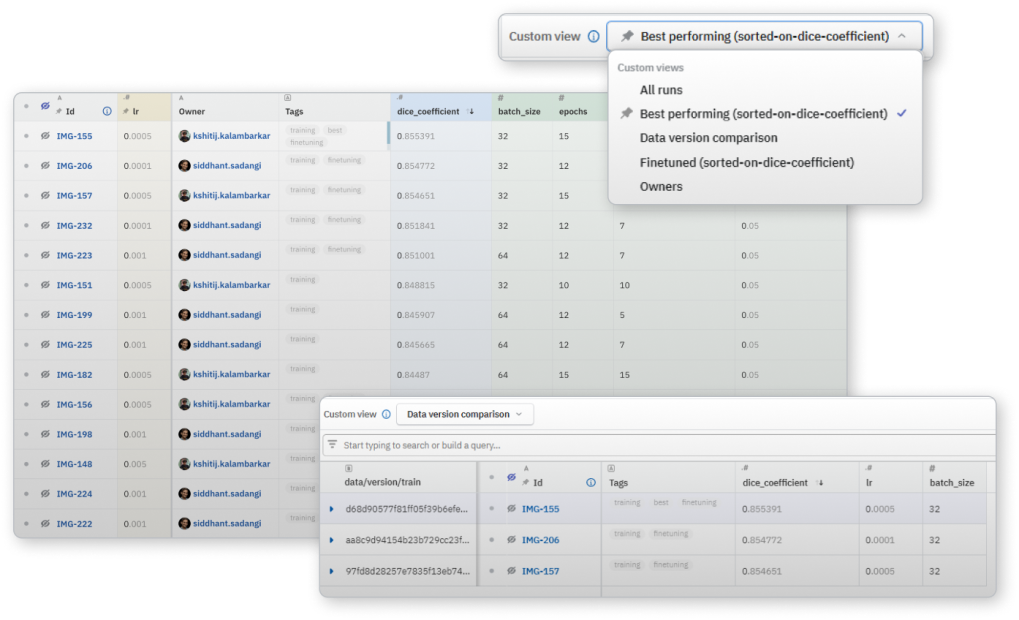
여러 실행에서 어떤 하이퍼파라미터 세트가 가장 좋은 지표를 생성하는지 빠르게 파악하고, 관심있는 매개변수 및 측정항목 범위를 탐색합니다.
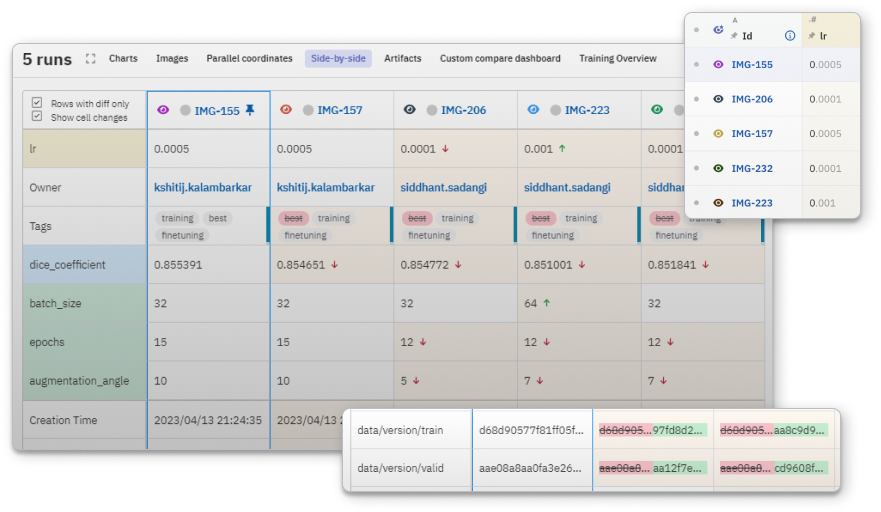
단일 지표를 병렬로 비교하여 앞으로 진행할 모델을 결정하는 데 필요한 폭넓은 시각을 확보할 수 있습니다.
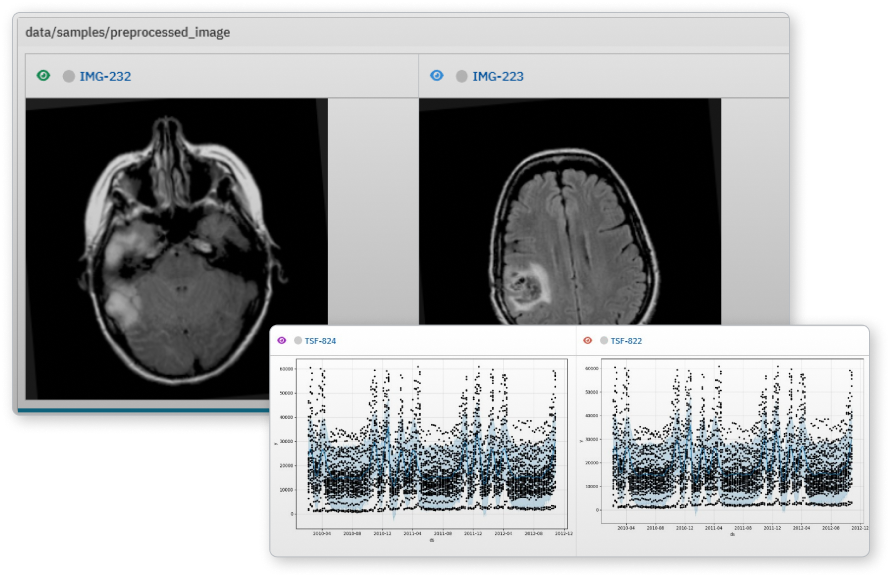
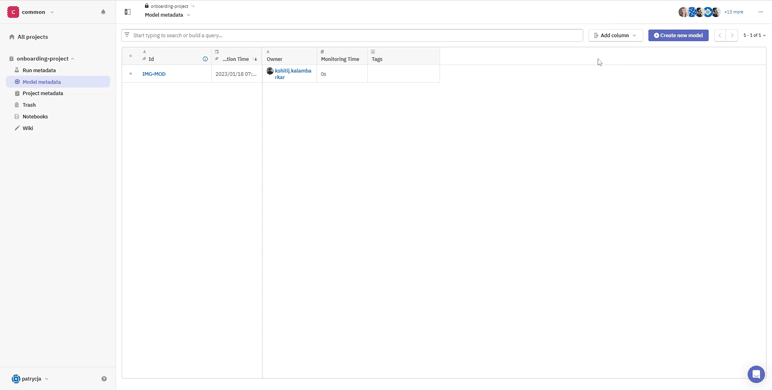
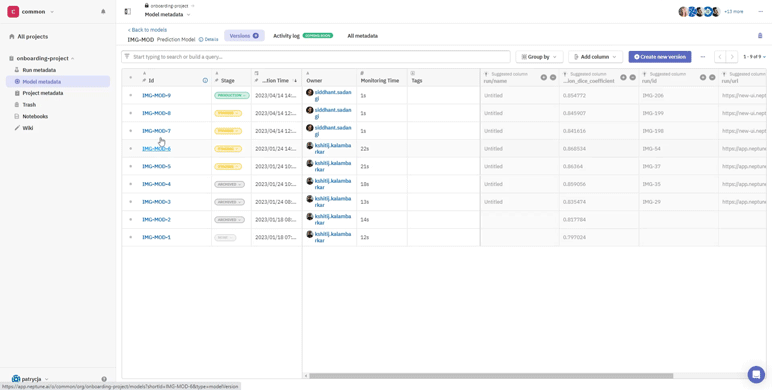
이미지 메타데이터를 병렬로 비교하여 분류 및 물체 감지와 같은 컴퓨터 비전 문제를 해결하거나, 이미지로 기록된 모든 메트릭을 동시에 빠르게 분석할 수 있습니다.
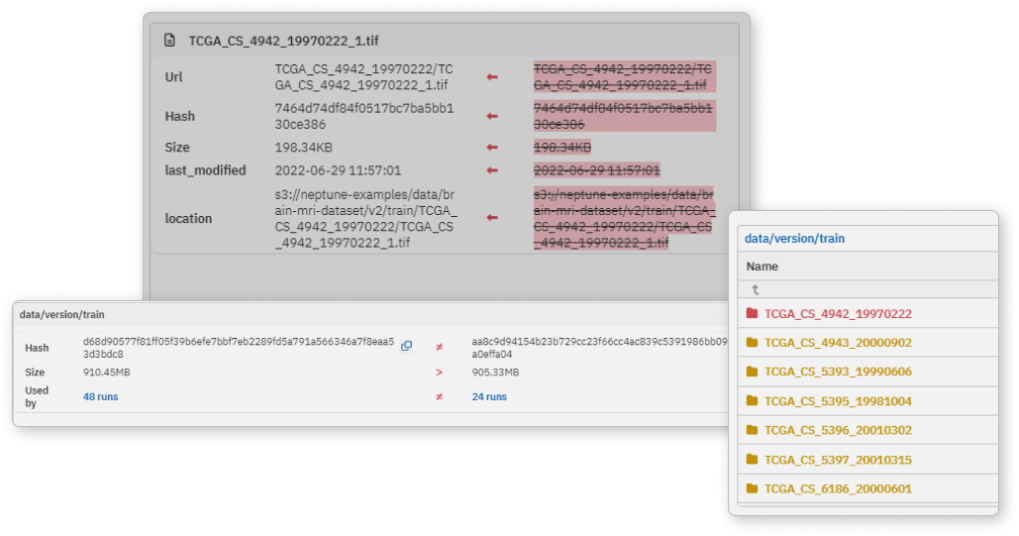
소스 실행과 대상 실행 간의 데이터 세트의 차이를 쉽게 비교할 수 있습니다. 경로, 크기, MD5 해시를 대조하세요. 모델 성능 변화의 원인이 매개변수인지 데이터인지 파악할 수 있습니다.
서로 다른 Epoch, 데이터 조각 간의 손실 또는 정확도 메트릭을 비교하여 특정 모델이 예측값에 더 빠르게 수렴하거나 또는 벗어나는 이유를 확인할 수 있습니다.
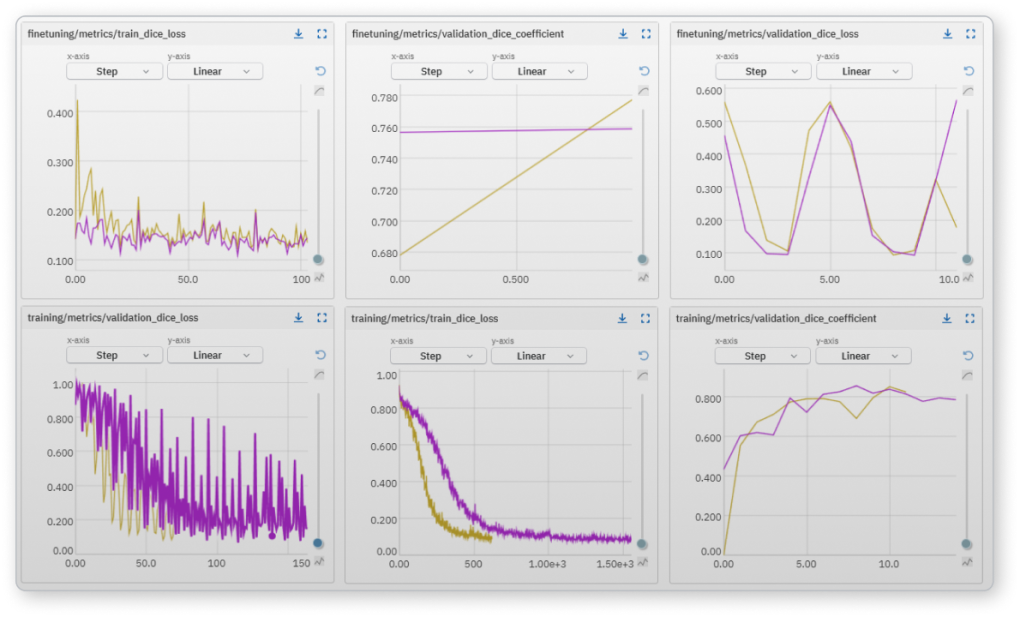
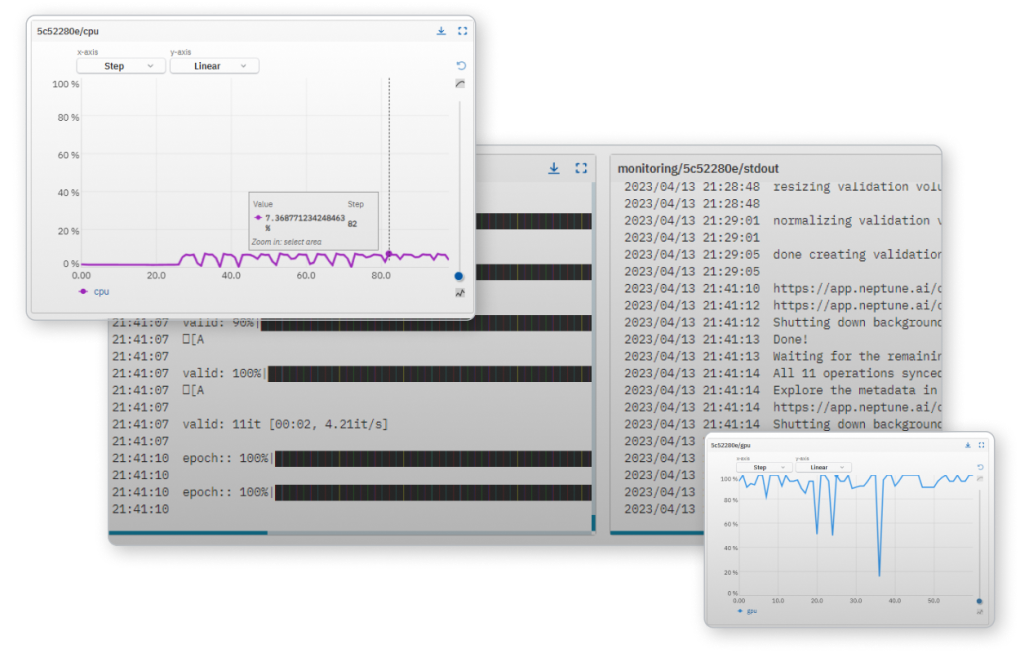
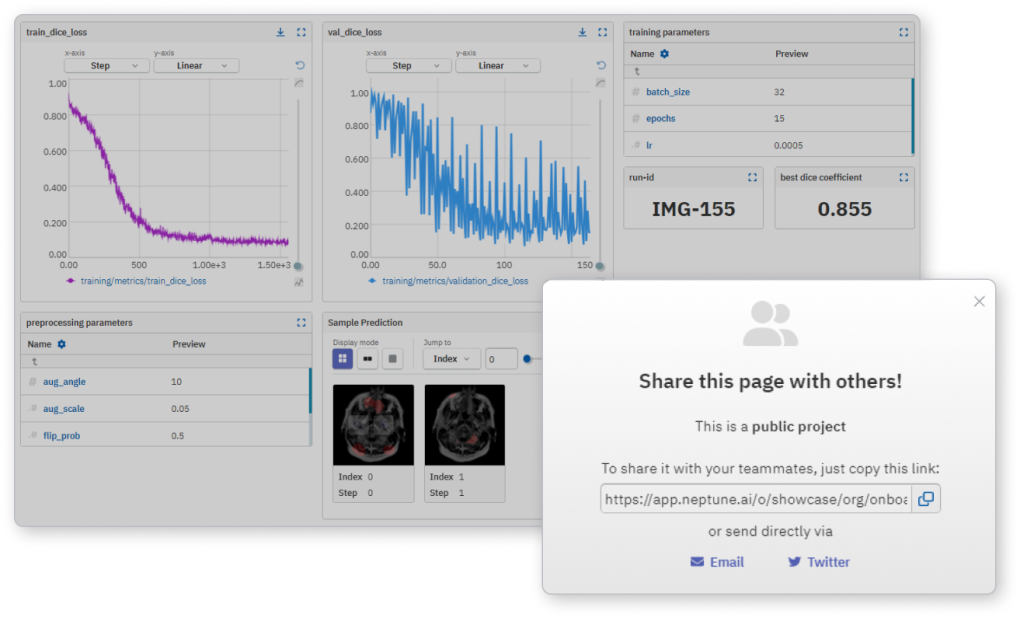
모델 성능의 실시간 피드를 통해 학습 상태에 대한 지속적인 인사이트를 확보하세요.
실험 전반에 걸쳐 하드웨어 사용량을 모니터링하여 학습의 병목 현상을 제거하세요.
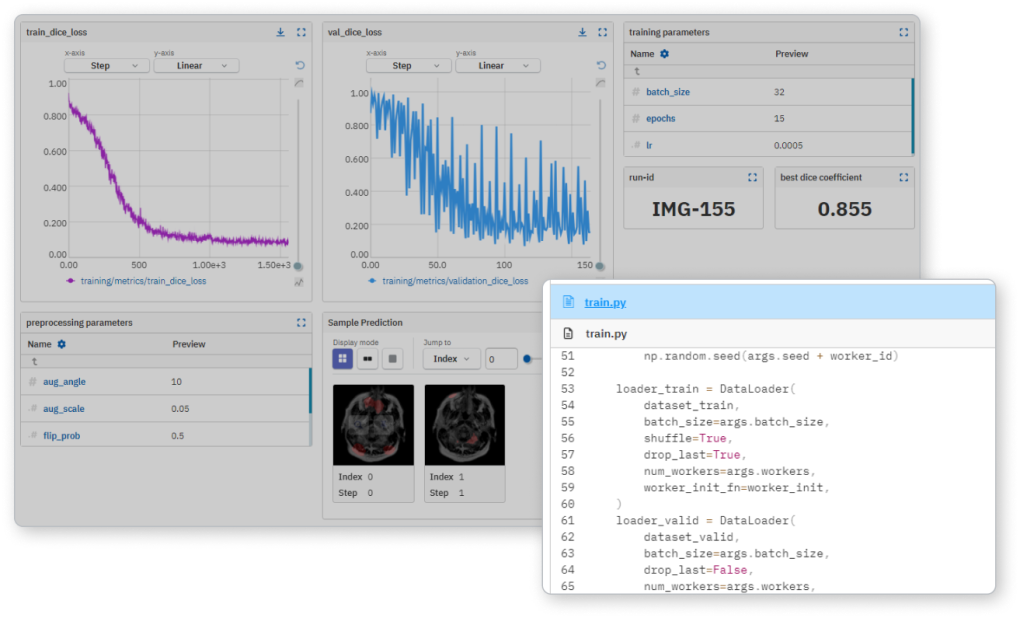
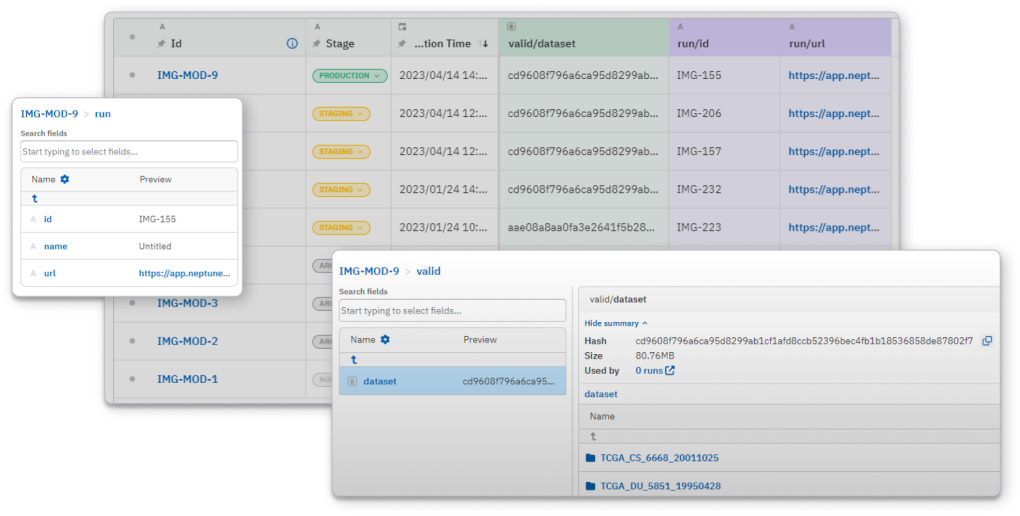
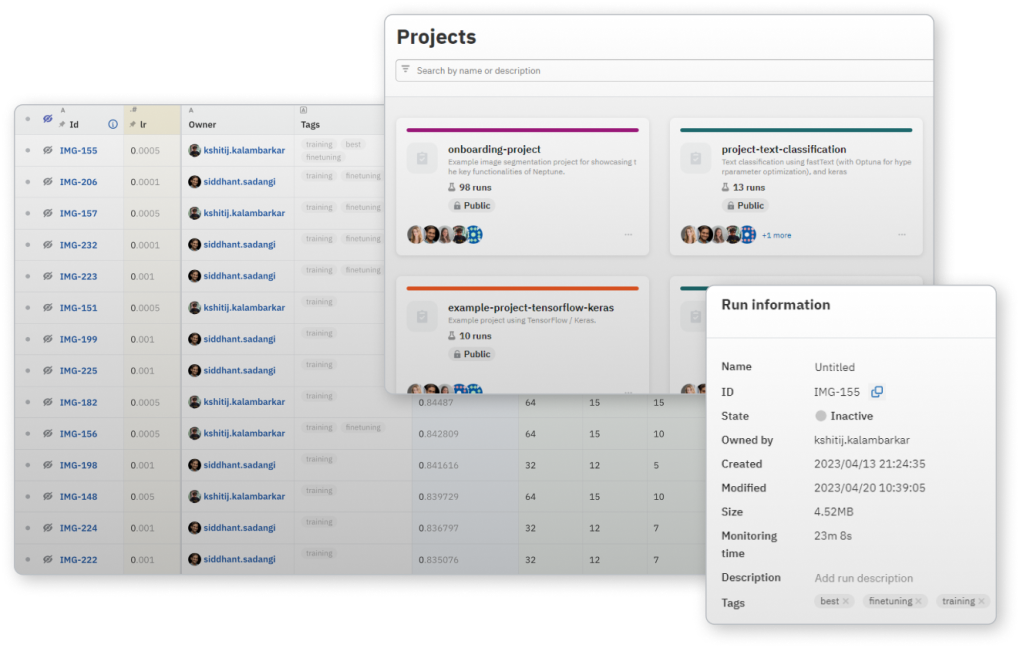
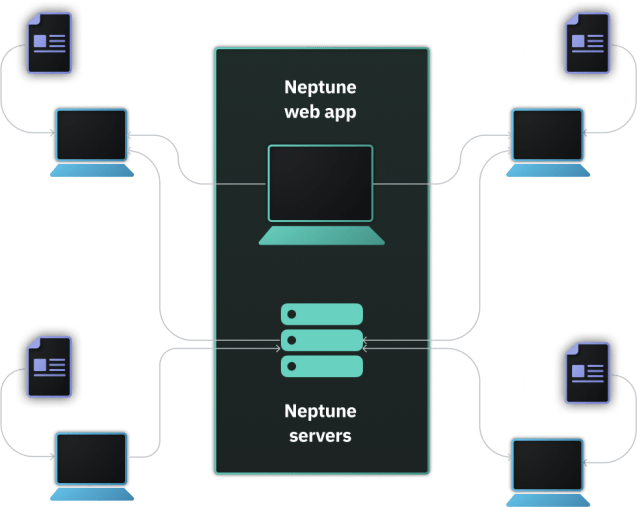
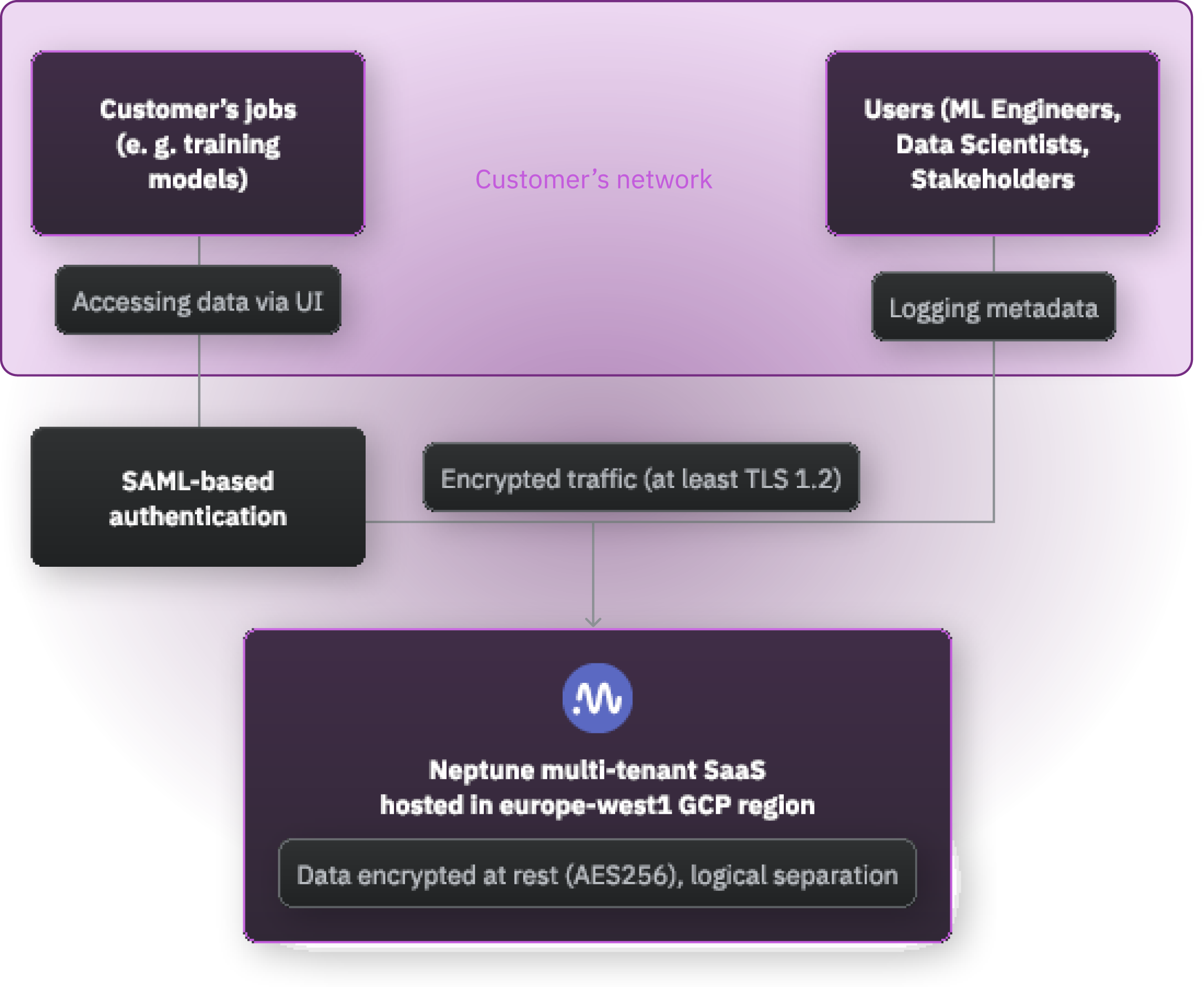
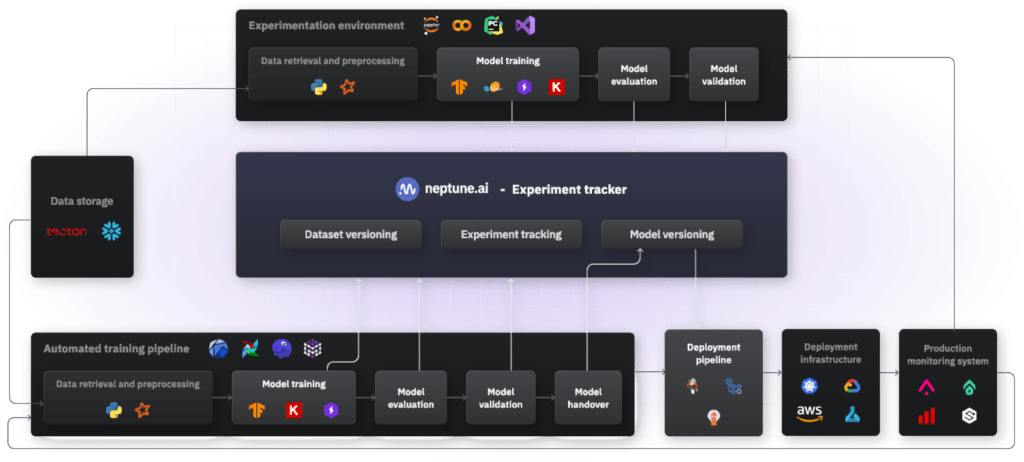
메타데이터를 Neptune 서버에 저장하고 Neptune 의 유지 관리 및 성능은 본사에서 처리됩니다.
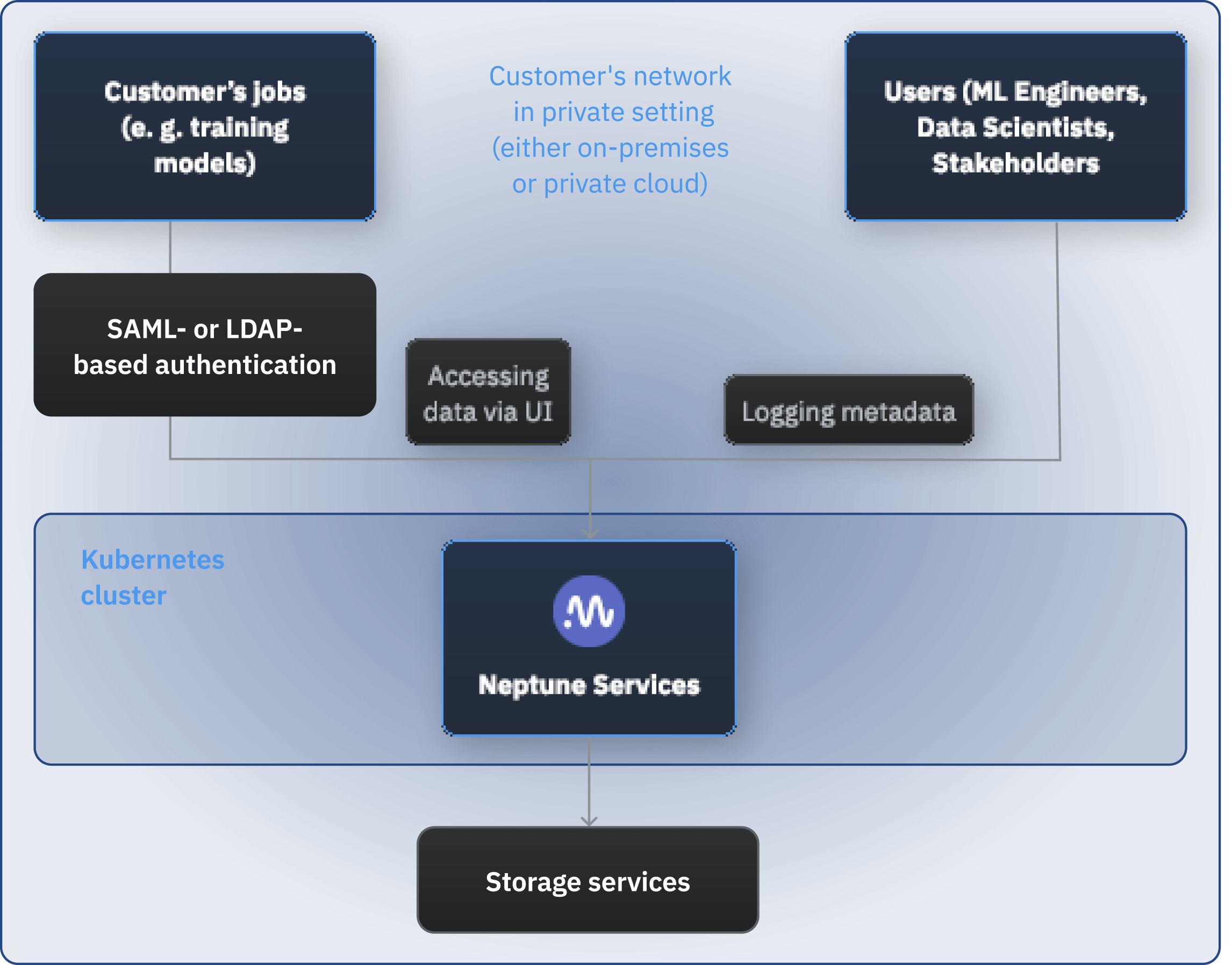
자체 인프라 또는 프라이빗 클라우드, Kubernetes 클러스터 또는 내부적으로 Kubernetes 클러스터를 실행하는 가상 머신에 Neptune 을 배포할 수 있습니다.