현재 인공지능(AI) 분야에서 AI 모델을 효율적으로 배포하고 확장하는 것은 개발자와 조직에게 주요한 도전 과제 입니다. Nvidia의 Inference Microservices (NIM)는 자체 호스팅 및 하이퍼스케일 AI 애플리케이션을 모두 지원하는 매우 유연한 솔루션을 제공하고 있습니다. 이 포스트에서는 개발자 관점에서 Nvidia NIM의 실용적인 응용, 유연성 및 확장성을 중점으로 분석해보겠습니다.
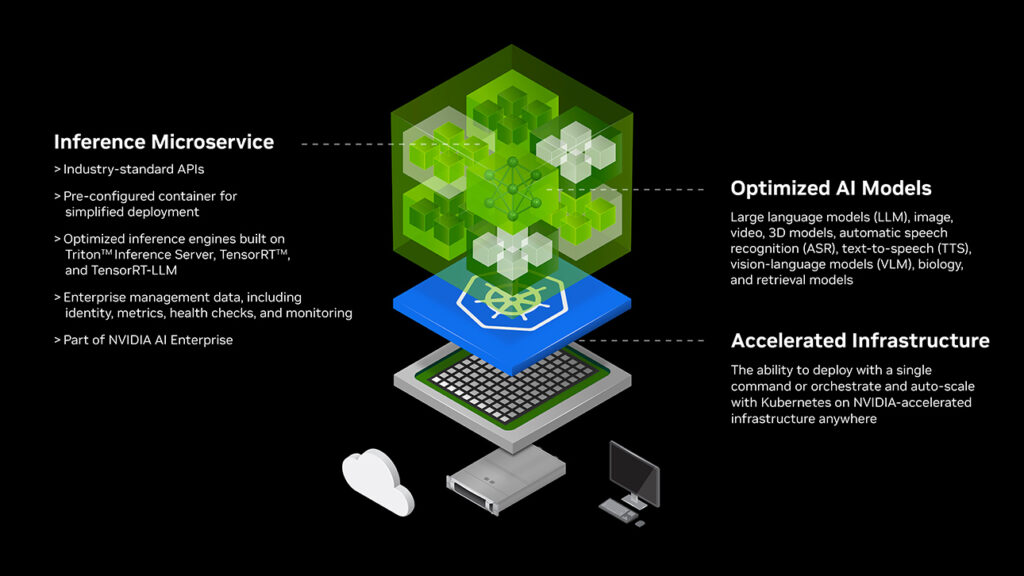
조직이 점점 더 AI를 운영에 통합함에 따라 대규모 언어 모델(LLM) 및 생성 AI와 같은 복잡한 AI 모델을 배포하고 확장해야 하는 과제에 직면해 있습니다. AI 모델은 낮은 대기 시간, 높은 처리량 및 비용 효율적인 운영을 보장하기 위해 강력한 인프라가 필요하지만, 기존의 배포 방법은 이러한 요구를 충족하기 어려워 새로운 접근 방식이 필요합니다.
자체 호스팅의 유연성
개발자로서 우리는 특히 민감한 데이터나 특정 규정 준수 요구 사항을 처리할 때 종종 배포에 대한 제어가 필요합니다. Nvidia NIM은 AI 모델을 온프레미스나 프라이빗 클라우드에 배포할 수 있도록 자체 호스팅 기능을 제공합니다. 이 유연성은 데이터 주권을 보호하면서 동시에 규제 요구 사항을 충족하는 데 매우 효과적입니다. 또한 Kubernetes와 Docker를 비롯한 다양한 배포 환경을 지원하여, 시스템 요구 사항에 따라 Meta의 Lama 3.1을 자체 시스템에서 직접 호스팅할 수도 있습니다.
최적화된 추론 성능
Nvidia NIM은 낮은 대기 시간과 높은 처리량을 실현하여, 추론 작업 최적화 시 우수한 성능을 보여줍니다. 이 기술은 엔비디아의 강력한 GPU와 최적화된 추론 엔진을 활용하며, 이는 실시간 애플리케이션에 특히 유용합니다. NIM의 성능을 최적화하면 챗봇, 추천 시스템 또는 기타 상호작용 AI 솔루션 구축의 운영 비용 절감과 사용자 경험 개선에 큰 도움이 됩니다.
Nvidia NIM으로 확장
하이퍼스케일 기능
대규모 AI 프로젝트를 진행하는 개발자에게 NIM의 하이퍼스케일 기능은 주요 이점입니다. NIM은 대규모 언어 모델(LLM) 및 기타 생성형 AI 모델과 같은 방대한 모델의 배포를 처리할 수 있습니다. 이는 콘텐츠 생성이나 대규모 데이터 분석과 같은 높은 처리량이 요구되는 애플리케이션에 특히 적합합니다. 또한, NIM은 Retrieval-Augmented Generation (RAG) 모델을 지원하여 고급 추론 및 데이터 합성을 가능하게 합니다.
개방형 에코시스템 및 통합
Nvidia NIM의 또 다른 두드러진 특징은 Triton Inference Server와 같은 Nvidia의 광범위한 생태계와의 통합입니다. 이 통합은 AI 모델을 배포하고 관리하는 과정을 간소화하여 일관된 환경을 제공합니다. NIM의 오픈 소스 접근 방식은 투명성과 협업을 중시하는 개발자 커뮤니티의 가치에 부합합니다. 이러한 개방성은 맞춤화를 용이하게 할 뿐만 아니라, 개발자들이 플랫폼의 기능을 확장하고 혁신할 수 있도록 장려합니다.
Nvidia NIM은 다양한 산업에서 혁신적인 변화를 이끌어낼 수 있는 강력한 도구입니다. 의료 분야에서는 진단 영상 처리와 환자 데이터 분석을 향상시키고, 금융 분야에서는 고급 사기 탐지와 위험 평가 모델을 구동합니다.
개발자들에게는 통제된 환경에서 정교한 AI 모델을 배포할 수 있는 능력이 매우 중요합니다. AI 기술이 발전함에 따라 Nvidia NIM과 같은 플랫폼은 혁신의 경계를 넓히고, 다양한 산업에 진보된 AI 솔루션을 제공하는데 중요한 역할을 할 것입니다.






